最近 "个人恶趣味" 持续泛滥。
博客的访问量、粉丝数一直是满足楼主个人虚荣心的好东西(原谅楼主也是凡人爱慕 "虚荣"),有时候我就在想,同一篇随笔,不同时间段发表是不是能获得不同的阅读量,换句话说,博文质量相同的情况下,哪个时间段的阅读量可能会多一些呢,于是决定让数据说话。(我会告诉你其实是想学习 node 嘛)
PS:爬取博客园并不想对博客园的服务器造成任何影响(事实也证明博客园的服务器是很刚的),只是为了学习之用,还望博客园的大大们海涵。
整体思路非常简单,采集发表在博客园首页的文章的 发表时间 以及 阅读量,进行分析。
博客园首页每页 20 篇随笔,采集 150 页,从 p51 到 p200,相应的 url 为 http://www.cnblogs.com/#p51 到 http://www.cnblogs.com/#p200,取每篇随笔的发表时间(小时)以及阅读量,最后求得该时段每篇随笔的阅读量平均值。

考虑到我和马云平均一下也是亿万富翁,得剔除一些有影响的数据。怎么说?比方有篇文章发表于 5 点,阅读量为 10k,并不是因为发表于 5 点导致阅读量很高,而是因为这篇文章确实有质量,如果它是 10 点发表,它的阅读量还是一样高,如果将这条数据算做有效数据,那么发表于 5 点的文章的平均阅读量一下子会被拉高,和 5 点这个时段并没有直接关系。根据经验,我把这个阈值定为阅读量 2000,也就是剔除了阅读量 2000+ 的数据。这也正是前面说的,"博文质量相同" 为前提,当然这个 "相同" 不可能是绝对的,只能相对来说。
后端方面,我希望能给前端提供一个接口,返回一个数组,该数组拥有 20*150 个对象,每个对象代表一条文章数据,它有两个 key 值,一个 key 为 postTime,表示发表时间(小时),另一个 key 为 viewTimes,表示阅读量。

比如上面这条数据,表示文章发表于 9 点(多),阅读量为 885。
这里我用 node 去爬博客园。
之前也用 node 并发爬过网页(详见 Nodejs - 如何用 eventproxy 模块控制并发),但是我不确定并发 150 个请求是不是会被博客园 "拒绝",好在我多虑了。
但是博客园的爬取和之前的爬虫还是有点区别,开始我以为爬取 http://www.cnblogs.com/#p51 到 http://www.cnblogs.com/#p200 即可,后来发现不对劲,它们的爬出来的页面 HTML 源代码都是一样的,都是博客园首页,才恍然大悟到博客园的翻页是 ajax 请求的(不知道 phantomjs 能不能得到类似的请求之后的页面源码),好在 SuperAgent 模块不仅能 get,还能 post。我们把这条请求抓出来看看:

用 SuperAgent 伪造 post 请求:
superagent .post('http://www.cnblogs.com/mvc/AggSite/PostList.aspx') .send({"CategoryType":"SiteHome","ParentCategoryId":0,"CategoryId":808,"PageIndex":i,"ItemListActionName":"PostList"}) .end(function (err, sres) { // callback // ... });接下去就不难了,用 eventproxy 模块控制并发,完成 150 个页面数据的抓取后,进入 after 回调;用 cheerio 模块对页面进行分析,得到需要的数据;通过 express 模块进行展示。这部分具体可以参考 node系列 的前两篇文章。
node 部分具体代码可以参考 Github
前端方面,需要进行数据的直观展示。
一开始想的是用 ajax 去请求接口,但是 node 比 php 复杂多了,不大好搞,我也在 cnode 社区提了个 问题,解答如下:
首先你没理解ajax技术的本质1. 让你的node能在浏览器端输出 hello world 参见http://www.nodebeginner.org/index-zh-cn.html2. 在你的页面端 js,跑 ajax 尝试去获取这个 hello world。如果涉及到跨域,请采用 fs 文件系统 + 设置 mime 的方式自己做 fs 服务器输出 page。 感觉有点复杂,毕竟文件系统什么的都没接触过,还好也有了解决方案,决定用 jsonp 进行跨域。
在调研了几款 Javascript 图表库后,最后选择了 chart.js 进行数据渲染,主要是它比较轻巧,很适合做简单的 demo。
接下去就非常简单了,将爬虫采集到的数据在 jsonp 回调函数中进行分析即可,分析的数据传入图表库的接口中,完成图表的渲染。
前端部分具体代码可以参考 Github
最后来看看成果吧。
首先统计的是是各个时间段发文总量,这个图表没有剔除数据,共 3000 条。

由图可以看出博客发表在 16点、17点 达到了高峰,个人猜测可能是快下班了,手头上的活都已经干完了,正好有时间可以总结总结。而 0-8 点以及 12-13 点明显处于谷值,这也不难理解,毕竟是睡觉时间以及午休时间。其他各个时间段的数据差异不大。
再来来看看各时段发文的平均阅读量(剔除了阅读量 2000+ 的数据):
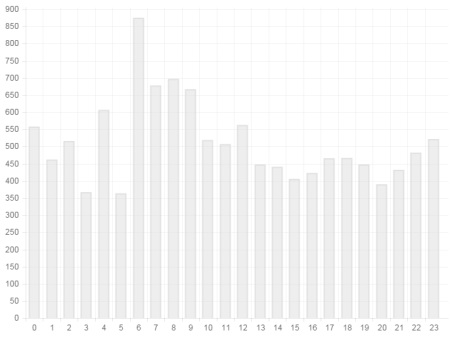
由图中可以看到,6 点发的文章阅读量 "鹤立鸡群" 啊,平均可以斩获 875 的访问。而 7-9 点发表的文章阅读量也紧随其后,这不难理解,6 点发表的文章正好可以被上班途中的人阅读到,一般 6-8 点发文的量并不多,这样你的文章就有很大的概率被上班途中的人看到。而 7-9 点也是一样的道理,早上到公司,打开浏览器,看看博客园首页,这几乎成了很多人的 "惯性",所以这个时间点的发文阅读量会相对大些。
其他一些时间点的数据相对平均,12 点又迎来一个小高峰,吃完午饭,浏览下博客园也是常事。
所以,程序员们,早起 6 点发文吧!当然,程序员们才不会干这种事,这种事交给定时脚本来干就好了,这个就是后文了。
如果你有兴趣,还可以研究下周末发文的阅读量和工作日的区别(据说周末发文没人看哦)。
本文所有代码可在我的 Github 中找到。
转载说明:欢迎转载本站所有文章,如需转载请注明来源于《绝客部落》。
本文链接:https://juehackr.net/zawen/93.html
